Part 2 - closer look at Rasa components

Introduction
In the previous tutorial, we created a very simple bot to launch our Rasa journey. In this tutorial, we will take a closer look at the basic components that the Rasa framework comes with when we initialized our first bot. Before we dive into this, let's first understand how this framework operates in the background.
How does Rasa framework work?
Rasa framework contains two libraries, Rasa Core and Rasa NLU. The first library represents the natural language understanding of the framework. It can be the interpreter that classifies intents and extracts entities based on machine learning techniques to make the bot able to understand the user inputs. The second library is the engine of Rasa, operated by a deep learning neural network called LSTM (Long Short-Term Memory) to teach the bot how to make responses and give appropriate replies to the user.
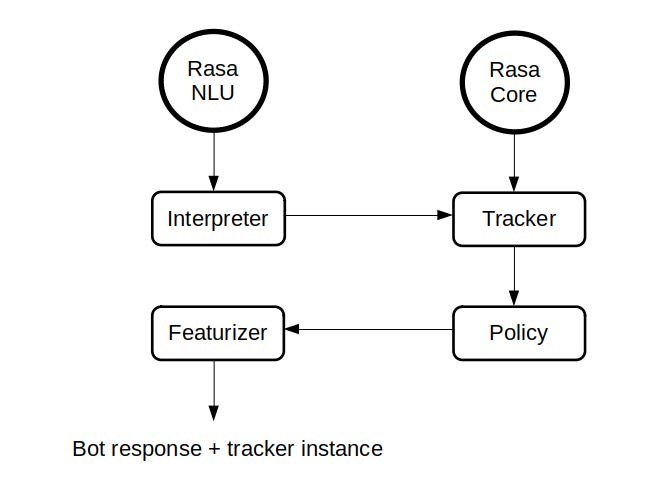
The story begins when the user sends an input to the bot. Here, the Rasa NLU will interpret the input to classify intents and extract entities and other particular information. Next, Rasa Core comes to manage and maintain the conversation state using the following parameters to execute the action needed and send a message to the user:
Tracker is used to keep track of the conversation history and save it in memory.
Policy is the decision-maker of Rasa, it decides on what action the bot should take at every step in the conversation.
Featurizer with the help of Tracker, it generates the vector representation of the current conversation state so the action can pass later a Tracker instance after every interaction with the user.
Rasa Components
When you run the rasa init command, the framework creates an initial structure for your project. With this structure, developers have the freedom to customize their bot's settings to fit their purposes. Therefore, each Rasa project contains the following structural components that form the basic skeleton of your bot:
Data
The most essential part of the process of building a bot is the data on which your bot will be based on it to learn how to recognize the user inputs. Rasa comes with different types of training data to train your bot, they vary in terms of structure and functionality and can be determined by the following top-level keys:
NLU (nlu.yml)
The purpose of using NLU (Natural Language Understanding) is to identify and extract the structured information from user inputs that can include intents, entities, and other extra information like regular expressions to improve the bot performance. The following shows a basic example of how NLU is structured:
version: "3.0"
nlu:
- intent: greeting
examples: |
- hey
- hi
- hello
- hola
- halloStories (stories.yml)
It represents and manages the conversation flow between the user and the bot. Here, the user inputs are defined as intents which are just the identifiers you defined in nlu.yml. The bot responses are defined as actions. In other words, Stories define the dialog tree. The dialog tree is actually a graph - connections between bot states. Each state is something the bot will do or say. The edges or transitions between states are the actions or statements the user makes. So the stories create the design of the conversation that determines the steps of the entire interaction. Rasa structures stories in the following manner:
version: "3.0"
stories:
- story: greet
steps:
- intent: greeting
- action: utter_greeting
- intent: howrey
- action: utter_howreyRules (rules.yml)
Another type of training data is called rules, designed to handle some specific intents in your conversation dialogue always with the same response. Meaning that rules are not able to respond appropriately to unseen user inputs as intents and stories do. This is how rules are structured in Rasa:
version: "3.0"
rules:
- rule: say the following at anytime user says something like
goodbye
steps:
- intent: goodbye
- action: utter_goodbye Actions
Too simply, actions is where you can automate the bot to respond to the user inputs based on intents and stories. Rasa comes with five types of actions you can use to interact with user messages:
Responses
Default actions
Custom actions
Form actions
Slot validation actions
You probably noticed one type of these actions above in rules and stories examples. It starts with utter_. Anyway, don't stress your mind with that at the moment, we will discuss each of these actions later in the next blogs.
Domain (domain.yml)
Domain is the environment that meets the bot components, there you can import your intents, entities, actions, and other structured information and settings together to configure how the bot should operate. The following gives an example of what a domain file looks like:
version: "3.0"
intents:
- greeting
- howrey
- positivemood
- negativemood
- whory
- howoldy
- wherey
- whatint
- thankyou
- goodbye
actions:
- action_restart
responses:
utter_greeting:
- text: |
hello there, how are you?
buttons:
- title: "great"
payload: "/positivemood"
- title: "super bad"
payload: "/negativemood"
utter_howrey:
- text: |
pretty good, what about you?
- text: |
awesome as always, how are you?
utter_positivemood:
- text: |
awesome.
- text: |
great.
utter_negativemood:
- text: |
no worries, life happens.
- text: |
don't worry, this is temporary.
utter_whory:
- text: |
I'm astro.
- text: |
You can call me astro.
utter_howoldy:
- text: |
quite young.
- text: |
I'm still young by your standards.
- text: |
younger than you.
utter_wherey:
- text: |
million light years away.
- text: |
I come from andromeda.
utter_whatint:
- text: |
I am interested in a wide variety of topics, and read
rather a lot.
- text: |
I'm curious about everything and I love reading useful
topics.
utter_thankyou:
- text: |
you are welcome.
- text: |
my pleasure.
- text: |
de nada.
utter_goodbye:
- text: |
glad to chat with you, come back again.
- text: |
bye, take care.
session_config:
session_expiration_time: 60
carry_over_slots_to_new_session: trueConfig (config.yml)
As the name suggests, this configuration file determines some dependencies needed to train your model. It allows you to customize and adjust the pipeline and policies to make appropriate predictions. Also, this file comes with a default model configuration in case you don't need any adjustment.
Models
This directory saves your trained models into .gz format. Here is an example of a trained model: 20220131-160359-teal-holder.tar.gz.
Tests (test_stories.yml)
Rasa allows you to validate and test the conversation flow of your bot to see how can generalize to unseen conversation paths by running test stories. The following shows an example of a test story:
version: "3.0"
stories:
- story: greet
steps:
- user: |
hello
intent: greeting
- action: utter_greeting
- user: |
how are things?
intent: howrey
- action: utter_howreyEndpoints (endpoints.yml)
This file contains utilities that can help your bot be exposed to a server to run your custom actions, keep track of the conversation and store it in memory or SQL database, and stream all conversation events.
Credentials (credentials.yml)
This file contains detailed credentials for different messaging channels that the bot used.
Training data format
Rasa uses YAML to manage your training data, including nlu, stories, rules, and domain. The training data can be combined into one single file, while domain can also be split into multiple files. Note that the top-level key (eg. nlu, stories) should be always determined at the beginning of each training data type.
What’s next?
Hopefully, this tutorial helps you understand your Rasa project structure and what each bot component is used for. In the next blog, we will learn in detail how to create NLU data for our bot with other structured information like entities and regular expressions.
In case you missed it, here is the link to my previous blog on how to create a Rasa project:
Part 1 - getting started with your first Rasa bot
If you have any questions, leave them in the comments below or feel free to contact me on LinkedIn. Don’t forget this post is public so feel free to share it.